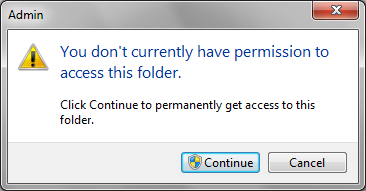
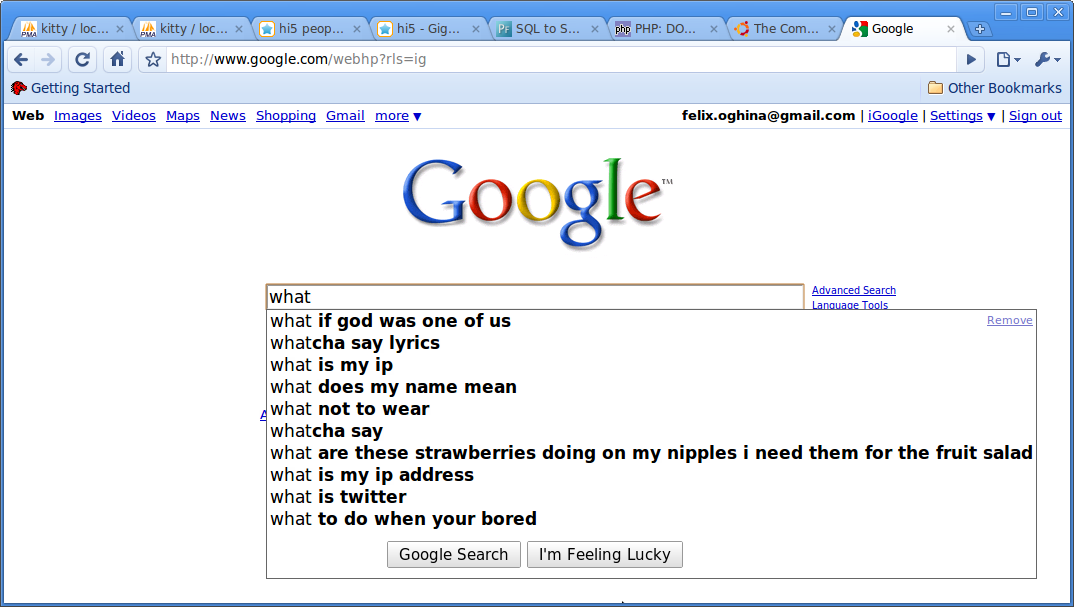
Maximum score
2 years ago
DOMElement that gets the inner/outerHTML of the element. There are a few solutions in the comments and on other blogs, but they loop through all the childNodes in order to get the innerHMTL. Getting the outerHTML is much easier (no looping) and just as useful:
function outerHTML($e) {
$doc = new DOMDocument();
$doc->appendChild($doc->importNode($e, true));
return $doc->saveHTML();
}
Still, I'm not sure that is the most optimal way of doing it. It seems that DOMDocument::saveXML accepts an optional DOMElement parameter which, when specified, causes the function to return only that element's XML. You could rewrite our outerHTML function like this:
function outerXML($e) {
return $e->ownerDocument->saveXML($e);
}
ssh-copy-id has known problems with handling non-standard ports (e.g. connecting to a different port than 22). To overcome this issue, use a command like:
$ ssh-copy-id "user@host -p 6842"
.data
prompt1: .asciiz "a: "
prompt2: .asciiz "b: "
newline: .asciiz "\n"
.text
main:
# print prompt 1
li $v0, 4
la $a0, prompt1
syscall
# read in $t0
li $v0, 5
syscall
move $t0, $v0
#print prompt 2
li $v0, 4
la $a0, prompt2
syscall
# read in $t1
li $v0, 5
syscall
move $t1, $v0
# $a0 = $t0 + $t1
add $a0, $t0, $t1
# print result
li $v0, 1
syscall
# newline
li $v0, 4
la $a0, newline
syscall
# exit
li $v0, 10
syscall
References:
/*
A brainfuck intepreter written in C, complete with error checking so you
don't hurt yourself while, uh, brainfucking. Nothing really special about
the implementation and it is probably very poor performance-wise.
Author: Felix Oghină
License: (brain)fuck licenses!
*/
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
// by brainfuck standards (doesn't that sound funny?), the data pointer has
// 30,000 bytes at its disposal, but I hate hard-coding such stuff.
#define DATA_SIZE 30000
void usage() {
puts(
"Usage: brainfuck FILE\n"
"If FILE is ommited or is '-', standard input is read"
);
}
int main(int argc, char **argv) {
// used by the bf program
unsigned char *dataptr = malloc(sizeof(char) * DATA_SIZE);
// position of the data pointer
unsigned int datapos = 0;
// input file
FILE *input;
// level - deepness of brackets
// i - uh, you need explanation for this one?
unsigned int level, i;
// we will read chars from the input into r
unsigned char r;
// determine input
if (argc == 2) {
if (strcmp(argv[1], "--help") == 0 || strcmp(argv[1], "-h") == 0) {
usage();
return EXIT_SUCCESS;
}
else {
input = fopen(argv[1], "r");
if (input == NULL) {
puts("Error opening input file");
return EXIT_FAILURE;
}
}
}
else {
usage();
return EXIT_FAILURE;
}
// zero the data pointer
for (i=0; i < DATA_SIZE; i++) {
dataptr[i] = 0;
}
// start interpreting
rewind(input);
while (!feof(input)) {
r = (unsigned char) fgetc(input);
switch(r) {
case '>':
if (datapos < DATA_SIZE - 1) datapos++;
else {
puts("brainfuck error: pointer overflow");
return EXIT_FAILURE;
}
break;
case '<':
if (datapos > 0) datapos--;
else {
puts("brainfuck error: pointer underflow");
return EXIT_FAILURE;
}
break;
case '+':
dataptr[datapos]++;
break;
case '-':
dataptr[datapos]--;
break;
case '.':
putchar(dataptr[datapos]);
break;
case ',':
dataptr[datapos] = getchar();
break;
case '[':
if (dataptr[datapos] == 0) {
level = 1;
while (level != 0) {
r = (unsigned char) fgetc(input);
if (r == '[') level ++;
else if (r == ']') level --;
}
}
break;
case ']':
if (dataptr[datapos] != 0) {
level = 1;
while (level != 0) {
fseek(input, -2, SEEK_CUR);
r = (unsigned char) fgetc(input);
if (r == ']') level ++;
else if (r == '[') level --;
}
}
break;
}
}
return EXIT_SUCCESS;
}
/var/www/hello.php, the following URLs will load the same file:
mod_rewrite is if you need to have URLs like http://example.com/1234, you can't handle that with MultiViews (but you can handle http://example.com/article/1234).
<?php
define('CALLBACK', 'rtw_callback');
define('JS_FILE', 'nowplaying.js');
define('MAX_ENTRIES', 5);
define('SERIALIZE_FILE', './data');
function test_value($var) {
if ( strlen($var) && mb_strtolower($var) != 'unknown' && $var != '0' ) {
return true;
}
return false;
}
$song_info = array();
foreach ($_GET as $key => $value) {
if (test_value($value)) {
$song_info[$key] = $value;
}
}
$last_songs = unserialize(file_get_contents(SERIALIZE_FILE));
if ($last_songs === false) $last_songs = array();
elseif (count($last_songs) >= MAX_ENTRIES) {
while (count($last_songs) >= MAX_ENTRIES) {
array_shift($last_songs);
}
}
$last_songs[] = $song_info;
file_put_contents(SERIALIZE_FILE, serialize($last_songs));
file_put_contents(JS_FILE, CALLBACK . '(' . json_encode($last_songs) . ')');
?><div id="rtw_info">Loading...</div>
<button style="padding: 2px 3px; font-size: 0.6em; background: #454545; border: solid 1px #7f7f7f; color: #fff; font-weight: bold; float: right" onclick="rtw_newer()" title="Show more recent songs">></button>
<button style="padding: 2px 3px; font-size: 0.6em; background: #454545; border: solid 1px #7f7f7f; color: #fff; font-weight: bold" onclick="rtw_older()" title="Show older songs"><</button>
<script type="text/javascript">
rtw_songs = null;
rtw_curIndex = 0;
rtw_script_url = "http://znupi.no-ip.org/felix/nowplayingv2/nowplaying.js";
function rtw_callback(aSongs) {
// store the received data and show the last song played
if (rtw_songs == null || rtw_songs[0].title != aSongs[0].title) {
rtw_songs = aSongs;
rtw_curIndex = aSongs.length - 1;
rtw_update();
}
}
function rtw_refresh() {
var script = document.createElement('script');
script.src = rtw_script_url + "?" + Math.random();
document.body.appendChild(script);
setTimeout(rtw_refresh, 5000);
}
function rtw_older() {
if (rtw_songs === null) return;
if (rtw_curIndex > 0) {
rtw_curIndex --;
rtw_update();
}
}
function rtw_newer() {
if (rtw_songs === null) return;
if (rtw_curIndex < rtw_songs.length - 1) {
rtw_curIndex ++;
rtw_update();
}
}
function rtw_update() {
// update the DOM
var toFill = document.getElementById('rtw_info');
// first, clear everything in the div
while (toFill.childNodes.length) {
toFill.removeChild(toFill.childNodes[0]);
}
// now fill it according to what data we have
var curSong = rtw_songs[rtw_curIndex];
// no data:
if (curSong.length == 0) {
toFill.appendChild(document.createTextNode('Nothing currently playing.'));
}
// some data:
else {
var b;
if (curSong.title) {
b = document.createElement("b");
b.appendChild(document.createTextNode("Song: "));
toFill.appendChild(b);
toFill.appendChild(document.createTextNode(curSong.title));
toFill.appendChild(document.createElement("br"));
}
if (curSong.artist) {
b = document.createElement("b");
b.appendChild(document.createTextNode("By: "));
toFill.appendChild(b);
toFill.appendChild(document.createTextNode(curSong.artist));
toFill.appendChild(document.createElement("br"));
}
if (curSong.album) {
b = document.createElement("b");
b.appendChild(document.createTextNode("From: "));
toFill.appendChild(b);
toFill.appendChild(document.createTextNode(curSong.album));
toFill.appendChild(document.createElement("br"));
}
if (curSong.genre) {
b = document.createElement("b");
b.appendChild(document.createTextNode("Genre: "));
toFill.appendChild(b);
toFill.appendChild(document.createTextNode(curSong.genre));
toFill.appendChild(document.createElement("br"));
}
if (curSong.year) {
b = document.createElement("b");
b.appendChild(document.createTextNode("Year: "));
toFill.appendChild(b);
toFill.appendChild(document.createTextNode(curSong.year));
toFill.appendChild(document.createElement("br"));
}
if (curSong.duration) {
b = document.createElement("b");
b.appendChild(document.createTextNode("Length: "));
toFill.appendChild(b);
var len = parseInt(curSong.duration);
var mins = Math.floor(len / 60);
var secs = len % 60;
toFill.appendChild(document.createTextNode(mins + ":" + secs));
toFill.appendChild(document.createElement("br"));
}
}
}
rtw_refresh();
</script>
@wbm Agreed that android needs more market share before you should care.Do you think that's true? I beg to differ. Getting your foot in early can earn you recognition on a new platform pretty easily. Let me explain: if you were to develop some awesome app for the iPhone right now, you would find it at the bottom of an over saturated App Store, amongst mostly mediocre products which no one bothers to browse. Most iPhone users just install Facebook, some Twitter client and a couple of silly games. Instead, the Android Market is hungry for new apps (not only because it's new, but also because of the emphasis that Google puts on third-party development and the general openness of the platform), and getting a head start can really make a difference. Your application gets a lot more exposure on the Android Market and the chances of it becoming a hit later are much more increased. Sure, it's a bit more risk, but I think it's worth it.
URL oUrl = new URL(sUrl);
SAXParserFactory spf = SAXParserFactory.newInstance();
SAXParser sp = spf.newSAXParser();
XMLReader xr = sp.getXMLReader();
MyXMLHandler handler = new MyXMLHandler();
xr.setContentHandler(handler);
xr.parse(new InputSource(oUrl.openStream()));SAXException) and it will even stop loading data, which results in faster load times and less bandwidth usage.
import java.io.StringReader;
import java.net.URLEncoder;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import org.xml.sax.Attributes;
import org.xml.sax.InputSource;
import org.xml.sax.XMLReader;
import org.xml.sax.helpers.DefaultHandler;
import android.app.Activity;
import android.app.AlertDialog;
import android.app.Dialog;
import android.app.ProgressDialog;
import android.content.DialogInterface;
import android.content.Intent;
import android.os.AsyncTask;
import android.os.Bundle;
import android.view.LayoutInflater;
import android.view.View;
import android.view.ViewGroup;
import android.view.Window;
import android.widget.BaseExpandableListAdapter;
import android.widget.ExpandableListView;
import android.widget.TextView;
import com.tastekid.TasteKid.TasteKidUtils.Resource;
import com.tastekid.TasteKid.TasteKidUtils.ResourceList;
Thank God for Eclipse's Ctrl+Shift+O (yes, I know I bashed Eclipse before, but it seems to behave much more nicely under Ubuntu than under Windows -- it doesn't go above 300MB RAM usage).
$data = file_get_contents($url);
But no, in Java, no such easiness for you! I had to write my own helper function:
public static String getUrlContent(String sUrl) throws Exception {
URL url = new URL(sUrl);
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setRequestMethod("GET");
connection.setDoOutput(true);
connection.setConnectTimeout(5000);
connection.setReadTimeout(5000);
connection.connect();
BufferedReader rd = new BufferedReader(new InputStreamReader(connection.getInputStream()));
String content = "", line;
while ((line = rd.readLine()) != null) {
content += line + "\n";
}
return content;
}
Seems very hackish, especially the line starting with BufferedReader. The whole function is actually composed of bits of code found around the web. Bah, why didn't Google choose Python as their default programming language for Android?
$ svn add *
I did so, and three revisions later I was unable to commit anymore, because Eclipse had removed some of its automatically generated files and svn didn't know what to do with them. Here's what you have to have in your repository:
$ svn ls .@1
AndroidManifest.xml
TODO
default.properties
res/
src/
You don't need the rest.
Hello My Dear
How are you? i hope all is well with you, i hope you may not
know me, and i don\'t know who you are, My Name is Miss morin khalifa
i am just broswing now i just saw your email
it seams like some thing touches me all over my body, i started having
some feelings in me which i have never experience in me before, so i
became interested in you, l will also like to know you the more,and l
want you to send an email to my email aaddress
so l can give you my picture for you to know whom l am. I believe we
can move from here! I am waiting for your mail to my email address
above. (Remeber the distance or colour does not matter but love matters
alot in life) miss morin
I guess my e-mail address is so sexy it turned her on O.o
init.d script for it. This is the default one they tell you to use:
# chkconfig: 345 93 14
# description: will start FAH client as a service
cd /path/to/folding
./fah6 -verbosity 9 < /dev/null > /dev/null 2>&1 &
This doesn't seem to work for me, the process does not start. What I've found to work is this:
### BEGIN INIT INFO
# Provides: fah
# Required-Start: $local_fs $network $named
# Required-Stop: $local_fs $network $named
# Default-Start: 2 3 4 5
# Default-Stop: 0 1 6
# Short-Description: Start Folding@Home client
### END INIT INFO
# chkconfig: 345 93 14
# description: will start FAH client as a service
cd /home/felix/fah/
./fah6 -verbosity 9 < /dev/null > /dev/null 2>&1 &
There you go. Now you have no reason to not run this :)
Edit: No, it doesn't work. It seems init starts the script twice, which messes things up. I think this has something to do with runlevels, but I'm too tired to figure it out now. If anyone knows a solution, please comment.
// try to determine the IP address of the hostname
// if the hostname is actually an IP, gethostbyname() will return it unchanged
// if the hostname cannot be resolved, it will have the same behavior
$ip = gethostbyname($address);
// check if the resulting IP is valid
if ($ip !== long2ip(ip2long($ip))) {
echo "Invalid hostname or IP address";
}
 Here's the code:
Here's the code:
<?php
$W = 160; // width
$H = 60; // height
$L = 6; // length of the key
$BG = 'light'; // can be 'light' or 'dark', accorting to the background color of
// the page it will be on
$F = './DejaVuSans.ttf'; // path to true-type font file
function makeKey($length) {
// generate a random sequence of characters
$a = 'abcdefghijklmnopqrstuvwxyz';
$s = '';
for ($i=0; $i < $length; $i++) {
$s .= $a[mt_rand(0, strlen($a) - 1)];
}
return $s;
}
$img = imagecreatetruecolor($W, $H);
// make the image alpha-aware
imagesavealpha($img, true);
// make colors 'blend', not overwrite
imagealphablending($img, true);
// make the image transparent
imagefill($img, 1, 1, imagecolorallocatealpha($img, 0, 0, 0, 127));
// generate two random colors and decide which one goes where
$dark = Array (mt_rand(0, 126), mt_rand(0, 126), mt_rand(0, 126));
$light = Array (mt_rand(127, 255), mt_rand(127, 255), mt_rand(127, 255));
if ($BG == 'dark') {
$bg_color = imagecolorallocatealpha($img, $dark[0], $dark[1], $dark[2], mt_rand(64, 96));
$fg_color = imagecolorallocatealpha($img, $light[0], $light[1], $light[2], mt_rand(32, 64));
}
else {
$bg_color = imagecolorallocatealpha($img, $light[0], $light[1], $light[2], mt_rand(64, 96));
$fg_color = imagecolorallocatealpha($img, $dark[0], $dark[1], $dark[2], mt_rand(32, 64));
}
// write background static
$angle = mt_rand(20, 35);
for ($i=0; $i < 15; $i++) {
imagettftext($img, 12, $angle, 0, $i*15, $bg_color, $F, makeKey(30));
}
$key = makeKey($L); // you should store this in the user session to check it later
// write the actual key, in two parts
imagettftext($img, mt_rand(16, 22), mt_rand(10, 30), mt_rand(5, 30), mt_rand($H-16, $H-22), $fg_color, $F, substr($key, 0, 3));
imagettftext($img, mt_rand(16, 22), mt_rand(-30, -10), mt_rand($W/2+5, $W/2+30), mt_rand(16, 22), $fg_color, $F, substr($key, 3, 3));
// output the image
header("Content-Type: image/png");
imagepng($img);
?>
On my machine (Pentium DualCore @ 2.80Ghz) it generates images in 70-75ms. I think that's pretty fair. Also, it works with non-bundled GD versions, too, so you don't have to worry about that. Enjoy.
$HOME/Ubuntu One folder and synchronize its contents with the Ubuntu One servers. The main idea of it is that of syncing between computers -- you associate all your PCs/laptops with the same account and your files get automatically synced between them. However, I use it for another purpose -- backups. I back up my work and other stuff on Ubuntu One, 2GB is really enough (for me, at least). What's great is that they also provide a web interface to download / upload files from / to your account, so I can access my files wherever, whenever, from whatever.
Don't jump head first, though. You might want to have a look at Dropbox, too. The main advantages are:
/news/page-%x/ or /news.php?page=%x{assign}):
{assign var="putDots" value=3}
{assign var="border" value=2}
{assign var="curPage" value=$pagination.curPage}
{assign var="url" value=$pagination.url}
{assign var="totalPages" value=$pagination.totalPages}
{if $totalPages > 1}
<div class="pages">
<span>
{if $curPage > 1}
<a title="Previous Page" href="{$url|replace:'%x':$curPage-1}">««</a>
{/if}
{* Handle the first part of the pages -- up to the current one *}
{if $curPage > $putDots}
<a title="Page 1" href="{$url|replace:'%x':'1'}">1</a>
...
{section name=i start=$curPage-$border loop=$curPage}
{assign var="curPos" value=$smarty.section.i.index}
<a title="Page {$curPos}" href="{$url|replace:'%x':$curPos}">{$curPos}</a>
{/section}
{else}
{section name=i start=1 loop=$curPage}
{assign var="curPos" value=$smarty.section.i.index}
<a title="Page {$curPos}" href="{$url|replace:'%x':$curPos}">{$curPos}</a>
{/section}
{/if}
{* Current page *}
<a title="Page {$curPage}" class="current" href="{$url|replace:'%x':$curPage}">{$curPage}</a>
{* Handle the last part of the pages -- from the current one to the end *}
{if $totalPages - $curPage + 1 > $putDots}
{section name=i start=$curPage+1 loop=$curPage+$border+1}
{assign var="curPos" value=$smarty.section.i.index}
<a title="Page {$curPos}" href="{$url|replace:'%x':$curPos}">{$curPos}</a>
{/section}
...
<a title="Page {$totalPages}" href="{$url|replace:'%x':$totalPages}">{$totalPages}</a>
{else}
{section name=i start=$curPage+1 loop=$totalPages+1}
{assign var="curPos" value=$smarty.section.i.index}
<a title="Page {$curPos}" href="{$url|replace:'%x':$curPos}">{$curPos}</a>
{/section}
{/if}
{if $curPage < $totalPages}
<a title="Next Page" href="{$url|replace:'%x':$curPage+1}">»»</a>
{/if}
</span>
</div>
{/if}
/proc/uptime). Straight to the code:
function get_uptime() {
$file = @fopen('/proc/uptime', 'r');
if (!$file) return 'Opening of /proc/uptime failed!';
$data = @fread($file, 128);
if ($data === false) return 'fread() failed on /proc/uptime!';
$upsecs = (int)substr($data, 0, strpos($data, ' '));
$uptime = Array (
'days' => floor($data/60/60/24),
'hours' => $data/60/60%24,
'minutes' => $data/60%60,
'seconds' => $data%60
);
return $uptime;
}
<?php
function getALLfromIP($addr,$db) {
// this sprintf() wrapper is needed, because the PHP long is signed by default
$ipnum = sprintf("%u", ip2long($addr));
$query = "SELECT cc, cn FROM ip NATURAL JOIN cc WHERE ${ipnum} BETWEEN start AND end";
$result = mysql_query($query, $db);
if((! $result) or mysql_numrows($result) < 1) {
//exit("mysql_query returned nothing: ".(mysql_error()?mysql_error():$query));
return false;
}
return mysql_fetch_array($result);
}
function getCCfromIP($addr,$db) {
$data = getALLfromIP($addr,$db);
if($data) return $data['cc'];
return false;
}
function getCOUNTRYfromIP($addr,$db) {
$data = getALLfromIP($addr,$db);
if($data) return $data['cn'];
return false;
}
function getCCfromNAME($name,$db) {
$addr = gethostbyname($name);
return getCCfromIP($addr,$db);
}
function getCOUNTRYfromNAME($name,$db) {
$addr = gethostbyname($name);
return getCOUNTRYfromIP($addr,$db);
}
?>
If anyone needs this, I have exported the cc and ip tables from the 01-May-09 version of the GeoIP database (it's the latest one at this point in time).
Download: geoip.01-May-2009.sql.gz [773.5 KB]
Also, here's a little demo application that looks up IPs and/or hostnames: http://znupi.no-ip.org/felix/work/2/ip-lookup/ (which might be offline at times)
@ECHO OFF
C:\Python26\python.exe "%1"
echo.
PAUSE
@ECHO ON
Then, in Notepad++, I went to Run → Run..., type in C:\Python26\python.bat "$(FULL_CURRENT_PATH)", then Save... and assign a shortcut. Press that shortcut now with a python file opened and boom goes the dynamite. Enjoy :)
 Quite annoying. And this is nothing, one time it happened that Eclipse was using 700MB with only a couple of files open. I'm not sure whether this is Eclipse's fault or Java's fault, but I think it's a bit of both. Eclipse's fault is that it's a huge application with tons of features you will never ever use. Java's fault is that it was never designed to run desktop applications (in my opinion). Because Java runs in a virtual machine, it can not give memory back to the host OS, so it just keeps using more and more, until it explodes, creating a black hole in your motherboard where the memory chips used to live. Bah, end of rant.
Quite annoying. And this is nothing, one time it happened that Eclipse was using 700MB with only a couple of files open. I'm not sure whether this is Eclipse's fault or Java's fault, but I think it's a bit of both. Eclipse's fault is that it's a huge application with tons of features you will never ever use. Java's fault is that it was never designed to run desktop applications (in my opinion). Because Java runs in a virtual machine, it can not give memory back to the host OS, so it just keeps using more and more, until it explodes, creating a black hole in your motherboard where the memory chips used to live. Bah, end of rant.
<?php
/**
* JS on-the-fly compressor with caching *
* Uses JSMin by Douglas Crockford *
* Author: Felix Oghina *
*/
//-- Configuration --//
$JSMin = 'jsmin-1.1.1.php'; // path to the JSMin class file
$path = '.'; // this can be made dynamic by assigning a value from $_GET, although it may be unsafe
$cache = 'js.cache'; // this file will be used as cache. If it's in the same directory as $path,
// it should not end in .js
//-- End of configuration --//
// include the JSMin script
require_once $JSMin;
// first decide if we use the cache or not
$usecache = true;
$files = glob($path . '/*.js');
$maxtime = filemtime($files[0]);
foreach ($files as $file) {
$curtime = filemtime($file);
if ($maxtime < $curtime) $maxtime = $curtime;
}
if (!file_exists($cache)) {
$usecache = false;
}
elseif (filemtime($cache) < $maxtime) {
$usecache = false;
}
// send appropiate headers
header("Content-Type: text/javascript");
// we use the cache
if ($usecache) {
readfile($cache);
}
// we rebuild the cache
else {
$js = '';
foreach ($files as $file) {
$js .= file_get_contents($file);
}
$js = JSMin::minify($js);
// rewrite the cache
file_put_contents($cache, $js);
// output the js
echo $js;
}
// done
?>
This solution uses caching, so it only minifies after you change something in one of the JavaScript files. In our case, this reduces the number of requests from 5 to 1 and the total size by 6kb (that's six thousand characters). The only flaw (that I see) is that if you delete one of your JavaScript files, it won't update the cache. Although I see the problem, I don't see an immediate solution, so I won't bother with it. It's not like we're going to delete JavaScript files all the time.
